Backup with Restic
📅 Published: • Thomas Queste
Learn how to set up a secure, monitored backup system using Restic and Healthchecks.io.
This guide covers running Restic without root privileges, automating backups and cleanup, and getting notifications when things go right—or wrong.
TL;DR
Most interesting bits:
- Run Restic rootless
- Alerts by SMS and email with Healthchecks.io
- Full log sent by email
Restic Rootless
Given you want to backup some system folders, like /etc, /home, and so on, you may want to run Restic without giving it full access to your system.
The old solution would have been to run the software as root, or setting the setuid bit on the binary.
This is dangerous, as the attacker would have full access to your system, in write mode!
The solution comes from Restic documentation in the “Backing up your system without running restic as root” section.
The solution boils down to:
- Create a new user,
restic - Put the
resticbinary in$HOME/restic - Ensure restic and root own the binary
- Add the read capability to the binary
I will not repeat the instructions here, as they are very well documented in the link above.
Notice: any update to the restic binary requires to re-set the capability.
Running Restic
I have two scripts that are run by systemd timers: one for backup, one for prune.
Prune is to remove old backups, i.e. the ones that are not needed anymore (like if you keep only the last 7 days).
Create the bucket
Depending on whom you use as a storage provider, you may need to create a bucket. This is pretty straightforward, and you can follow the documentation of your provider.
In my case, I use Scaleway Object Storage, and I created a bucket named my-bucket.
The provided will give you a key, a secret, and a URL to access the bucket.
Credentials
The repository and credentials are stored in /home/restic/restic-env.sh:
export AWS_ACCESS_KEY_ID="MY_ID"
export AWS_SECRET_ACCESS_KEY="MY_KEY"
export RESTIC_REPOSITORY="s3:https://s3.fr-par.scw.cloud/my-bucket"
export RESTIC_PASSWORD="MY_PASSWORD"
Backup
The /home/restic/backup.sh will:
- backup the files according to the includes and excludes
- check some parts of the backups for errors (a percentage of the data)
- display the list of files that have changed since the last backup
- the duration of each operation
#!/bin/bash
set -euo pipefail
function secondsToHuman {
local startTime="$1"
local now=$(date +'%s')
local elapsed=$((now - startTime))
echo "$(( elapsed / 3600 ))h $(( (elapsed / 60) % 60 ))m $(( elapsed % 60 ))s"
}
function backup {
local startTime=$(date +'%s')
echo "## Backup starting... ➡️"
/home/restic/restic backup -v \
--exclude-file=/home/restic/restic-excludes.txt \
--files-from=/home/restic/restic-includes.txt
echo "## Done backup in $(secondsToHuman "$startTime") seconds"
}
function check {
local startTime=$(date +'%s')
echo "## Check backups... ➡️"
/home/restic/restic check -v --read-data-subset=10%
echo "## Done check in $(secondsToHuman "$startTime") seconds"
}
function diffLatestSnapshot {
local startTime=$(date +'%s')
echo "## Computing diff of latest snapshots... ➡️"
/home/restic/diff-latest-snapshot.sh
echo "## Done computing diff of latest snapshots in $(secondsToHuman "$startTime") seconds"
}
function main {
local startTime=$(date +'%s')
source /home/restic/restic-env.sh
backup
check
diffLatestSnapshot
echo "## All done in $(secondsToHuman "$startTime" ) seconds ✅"
}
main
The restic-includes.txt and restic-excludes.txt are lists of files to backup or exclude.
For instance, the restic-includes.txt could be:
/home/foo
/etc
And the restic-excludes.txt could be:
**/.cache
**/.local
Prune
The /home/restic/prune.sh script is run once a month (not on each backup) and will:
- forget the snapshots according to the retention policy
- list the current (remaining) snapshots
- run the
checkcommand of restic
#!/bin/bash
set -euo pipefail
function secondsToHuman {
local startTime="$1"
local now=$(date +'%s')
local elapsed=$((now - startTime))
echo "$(( elapsed / 3600 ))h $(( (elapsed / 60) % 60 ))m $(( elapsed % 60 ))s"
}
function forget {
local startTime=$(date +'%s')
echo "## Forget snapshots... ➡️"
/home/restic/restic forget -v \
--keep-last 28 \
--keep-daily 30 \
--keep-weekly 16 \
--keep-monthly 24 \
--prune
echo "## Done forget in $(secondsToHuman "$startTime") seconds"
}
function snapshots {
local startTime=$(date +'%s')
echo "## Snapshots starting... ➡️"
/home/restic/restic snapshots
echo "## Done snapshots in $(secondsToHuman "$startTime") seconds"
}
function check {
local startTime=$(date +'%s')
echo "## Check backups... ➡️"
/home/restic/restic check
echo "## Done check in $(secondsToHuman "$startTime") seconds"
}
function main {
local startTime=$(date +'%s')
source /home/restic/restic-env.sh
forget
snapshots
check
echo "## All done in $(secondsToHuman "$startTime" ) seconds ✅"
}
main
Note that there are some overlaps between the two scripts, feel free to make them yours.
Scheduling
My server uses Systemd, so let us declare services and timers:
- one service and one time for
backup - one service and one time for
prune
Create /etc/systemd/system/backup.service:
[Unit]
Description=Backup
After=network-online.target
Wants=network-online.target systemd-networkd-wait-online.service
OnFailure=notify-failure@%n.service
[Service]
Type=simple
User=restic
ExecStart=/home/restic/backup.sh
ExecStopPost=/usr/local/bin/notify-unit backup.service "healthcheck-io-id-for-backup-abc12"
# Make /usr, /boot, /etc and possibly some more folders read-only.
ProtectSystem=full
[Install]
WantedBy=multi-user.target
Note:
- The service is run as the
resticuser - On end, we run a script to notify of success and failure, passing the service name and the ID of the healthcheck on Healthchecks.io (more on that below)
- On complete failure, we run another service to be notified of errors
- We protect the system folders from being written to (optional, but why not)
Here is the Timer, /etc/systemd/system/backup.timer:
[Unit]
Description=Run Backup
Requires=backup.service
[Timer]
Unit=backup.service
OnCalendar=00:00
OnCalendar=13:00
# Run script given last scheduled run has been miss (reboot...)
Persistent=true
[Install]
WantedBy=timers.target
Note:
- Backup is run twice a day. I want to backup my work from the morning, and the work from the afternoon.
- The timer is
persistent, so if the server is rebooted, the next backup will be run as soon as possible, i.e. not miss a backup.
The prune service and timer are similar.
In /etc/systemd/system/prune.service:
[Unit]
Description=Prune backups
After=network-online.target
Wants=network-online.target systemd-networkd-wait-online.service
OnFailure=notify-failure@%n.service
[Service]
Type=simple
User=restic
ExecStart=/home/restic/prune.sh
ExecStopPost=/usr/local/bin/notify-unit prune.service "healthcheck-io-id-for-prune-efg567"
# Make /usr, /boot, /etc and possibly some more folders read-only.
ProtectSystem=full
[Install]
WantedBy=multi-user.target
And in /etc/systemd/system/prune.timer:
[Unit]
Description=Run Prune backups
[Timer]
Unit=prune.service
# Run the first monday of every month
# https://wiki.archlinux.org/index.php/Systemd/Timers
OnCalendar=*-*-01 01:00:00
# Run script given last scheduled run has been miss (reboot...)
Persistent=true
[Install]
WantedBy=timers.target
Note that pruning is run once a month, on the first Monday.
The goal is to tidy the snapshots and keep only the one we want/need.
Monitoring
I use Healthchecks.io to monitor the success and failure of the backups and prunes.
The service is free for a limited number of checks, and I find it handy to be notified by email and SMS when something goes wrong.
Healthcheck.io works by adding “Checks” that get a URL to be pinged at the specified schedule.
If the urls are not pinged, you get a notification.
Simple + Efficient = Awesome!
In my case, I defined two checks, one for backup and one for prune.
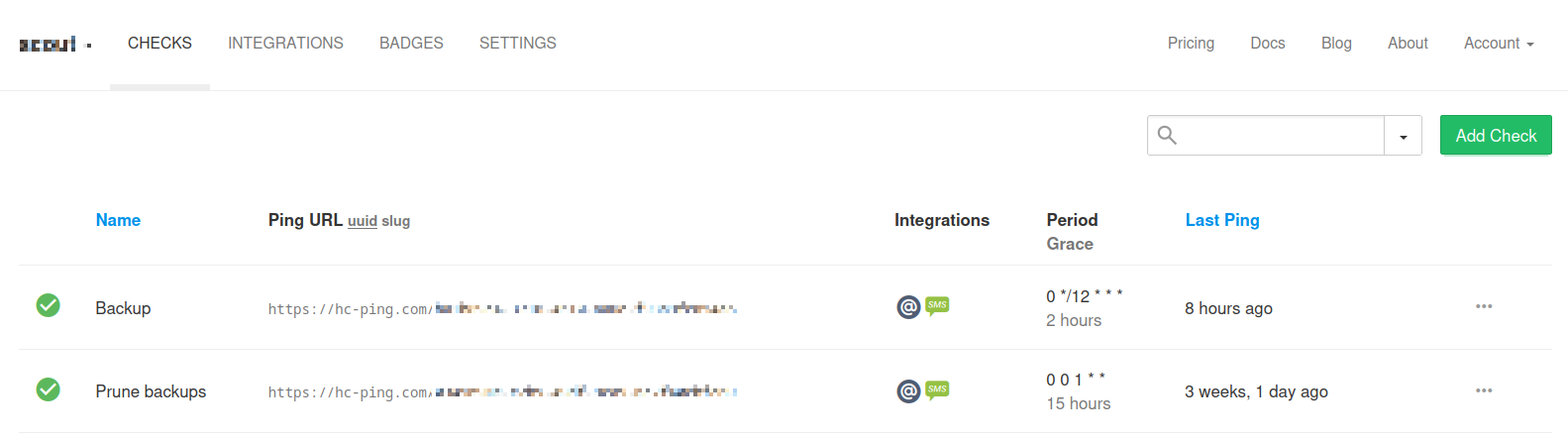
Notify success and errors
We will create two scripts in /usr/local/bin:
- one to collect the logs
- one to notify
The /usr/local/bin/notify-unit script will:
- collect the logs of the last run from the service, using
journalctland the service name specified as a param - notify Healthcheck.io
- send an email with the logs
#!/bin/bash
set -euo pipefail
UNIT="$1"
HEALTHCHECKIO_ID="$2"
function sendEmail {
local status=$1
local icon=$2
/usr/sbin/sendmail -t <<EOF
To: CHANGEME@CHANGEME.com
From: CHANGEME@CHANGEME.com
Subject: $icon $UNIT: $status
Content-Transfer-Encoding: 8bit
Content-Type: text/plain; charset=UTF-8
SERVICE_RESULT: $SERVICE_RESULT
EXIT_CODE: $EXIT_CODE
$(systemctl status --full "$UNIT")
----
$(journalctl -q _SYSTEMD_INVOCATION_ID=`systemctl show -p InvocationID --value $UNIT`)
EOF
}
if [ "$SERVICE_RESULT" = "success" ] && [ "$EXIT_STATUS" = "0" ]; then
sendEmail "Success" "💚"
curl -fsS --retry 5 --max-time 10 -o /dev/null "https://hc-ping.com/$HEALTHCHECKIO_ID"
else
sendEmail "Error" "⛔"
curl -fsS --retry 5 --max-time 10 -o /dev/null "https://hc-ping.com/$HEALTHCHECKIO_ID/fail"
fi
The second script, /usr/local/bin/notify-unit-failure, is used when the Systemd service completely failed to run.
With some thinking, as my setup is working, maybe this one is redundant and could be removed.
#!/bin/bash
set -euo pipefail
UNIT="$1"
/usr/sbin/sendmail -t <<EOF
To: CHANGEME@CHANGEME.com
From: CHANGEME@CHANGEME.com
Subject: ⛔ Systemd unit FAILED: $UNIT
Content-Transfer-Encoding: 8bit
Content-Type: text/plain; charset=UTF-8
$(systemctl status --full "$UNIT")
----
$(journalctl _SYSTEMD_INVOCATION_ID=`systemctl show -p InvocationID --value $UNIT`)
EOF
Note:
- You need a properly configured mail command (a
MTA) to be able to send emails. I usemsmtpunder the hood, and use MailJet as a relay. - You need to replace the emails with your own
Success email sample 💚
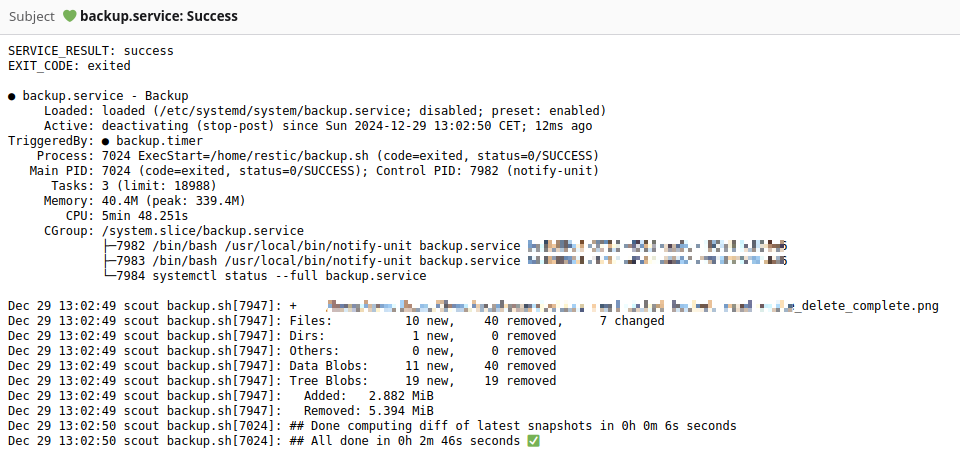
Conclusion
✅ And there you have it: a backup system that runs without root, sends you alerts, and actually tells you when something’s wrong.
The setup might look like a lot of moving parts, but once it’s running, you can finally stop worrying about backups and get back to breaking prod… I mean, being productive. 🔥🧯