Delightful experience with Anthropic Claude LLM
📅 Published: • Thomas Queste
Lately, I wanted to convert my list of books from a text file to JSON to give it a better structure.
Instead of writing a bunch of regexes and string tricks, I went for Anthropic Claude LLM.
The experience and results were impressive!
TL;DR
- Claude was learnt to recognize tags, eg.
<book></books> - The workbench handles variables, eg.
{{ BOOKS }} - You can evaluate your prompt with test cases
- Flawless, I got exactly the output specified, no hallucination, no wrong JSON, using
claude-3-5-sonnet-20240620 - Exhausted my credit in a few runs, learning that I should not have tried to process all my book list at once
Problem: I was not consistent
Today when I read a book, I simply add an entry in my books.txt with the title, author, read date, rating, sometimes a comment…
And I am not really consistent!
Sometimes I change the date format, or the rating, or forget to write the author’s name, or put the volume number in the title, or (long list of inconsistencies…).
Solution: a LLM
My first approach was simple code, parsing regexes and… I quickly failed.
So, why not use a smart LLM to extract structured data from my hazardous-non-strict grammar?
I went to Anthropic Claude, because it got impressive results in some tests I read.
The API is not free, but you can start with a free 5$ credit, enough for a start.
How it went: The Workbench
The workbench is a web interface where you can test your prompt and see the output.
A pitch then a prompt
I started with a simple sentence (basically the idea in my head) and asked Claude to generate a prompt from that “pitch.”
Prompt: Extract structured data from this list of books in french
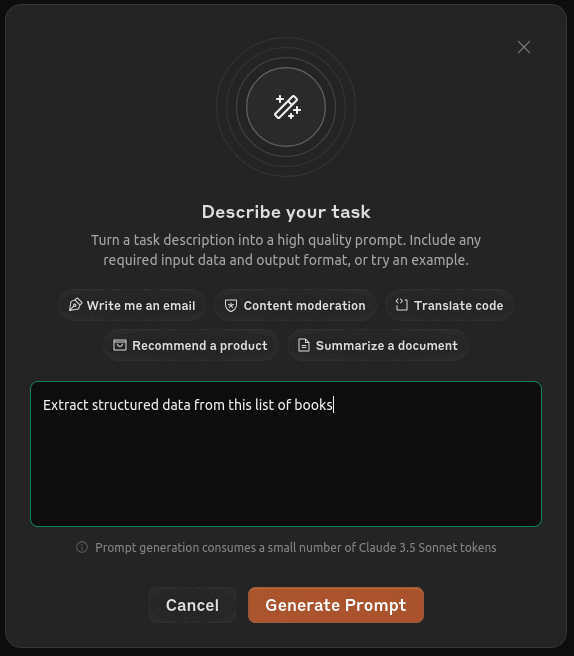
Claude generated a bigger and hopefully more precise prompt, with an example structure and some instructions for itself.
The temperature was already set to 0, which makes the model more deterministic and less creative.
After modifying the fields for my own (like rating, date read…), the prompt become this one:
You will be given a list of books in French. Your task is to extract structured information from this list and format it as JSON. Here is the list of books:
<book_list>
{{BOOK_LIST}}
</book_list>
For each book in the list, extract the following information:
1. Title (titre)
2. Author (auteur)
3. Description (description)
4. Rating (note)
5. Comment (commentaire)
6. Date Read (date de lecture)
7. Urls (liens)
Keep the JSON keys in English, but extract the values from the French text. If any information is missing for a particular book, use null for that field.
Format the extracted information as a JSON array of objects, where each object represents a book. Use the following structure:
```json
[
{
"title": "Book Title",
"author": "Author Name",
"description": "Book description",
"rating": 5,
"comment": "Reader's comment",
"dateRead": "2023-05-15",
"urls": ["https://somewebsite.com/book"]
},
// More books...
]
`` `
Note that the "rating" should be a number if available, and the "dateRead" should be in ISO 8601 format (YYYY-MM-DD) if possible.
Here's an example of how to structure a single book entry:
```json
{
"title": "Le Petit Prince",
"author": "Antoine de Saint-Exupéry",
"description": "Un conte philosophique sur l'amitié et la vie",
"rating": 5,
"comment": "Un classique intemporel, toujours aussi touchant",
"dateRead": "2023-04-10",
"urls": ["https://amazon.com/12345"]
}
`` `
Analyze the provided book list, extract the required information, and format it as a JSON array. If you encounter any ambiguities or difficulties in extracting certain information, use your best judgment to interpret the data.
Provide your final output enclosed in <json_output> tags.
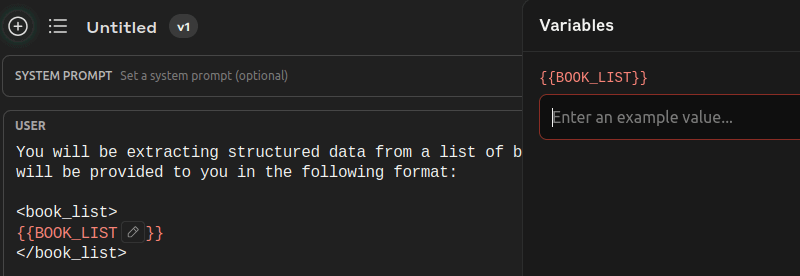
Variables
If you have sharp eyes, you may have noticed the special {{ BOOKS_LIST }} in red.
This is a variable that you can fill in a separate panel in the workbench:
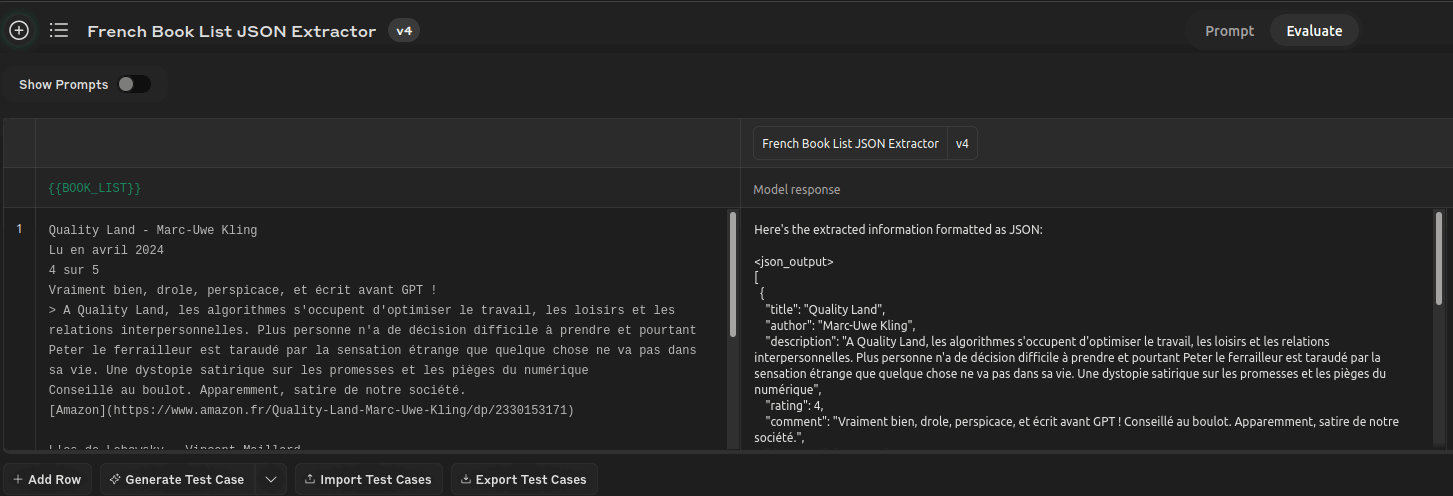
Evaluation
You can evaluate your prompt directly in the workbench, providing test cases:
The code
As for Google VertexAI, Claude gives you directly the code to execute in the API:
What failed, lessons learned
Input can be huge, but Output is limited and more expensive.
I have a big list of books (a few hundreds), and I tried to process them all at once.
For that, I copied my full list in the variable, and… only a few books were returned.
Yes, indeed, the output is limited to a few thousand tokens depending on the model, so you cannot process a big list at once.
Solutions:
- Chunk your list in multiple smaller lists
- Or, change the prompt and process books one by one, calling the LLM for each, which is actually more simple and can even reduce the prompt size, so the tokens, so the speed and cost
Conclusion
I had a good experience with Anthropic Claude LLM. 👍
The newest models are impressive, pretty consistent, and easy to use.
But there are real differences between LLM and their capacity.
For instance, I also used Gemini Flash on the same task, and the results were not as good as Claude.
It failed to output JSON and only that (no Markdown wrapper…). Same when I tried to get JSONL (one JSON per line).
Could be my prompt, could be the model…